基本情報技術者試験 令和元年度 秋季 午前 問9
配列と流れ図と回転をネタにした問題。
--------------------------
令和元年度 秋期 午前 問9
配列 A が図 2 の状態のとき、図 1 の流れ図を実行すると、配列 B が図 3 の状態になった。図 1 の a に入れる操作はどれか。
ここで、配列 A、B の要素をそれぞれ A( i, j )、B( i, j ) とする。

ア B( 7-i, 7-j ) ← A( i, j )
イ B( 7-j, i ) ← A( i, j )
ウ B( i, 7-j ) ← A( i, j )
エ B( j, 7-i ) ← A( i, j )
--------------------------
解説
配列 A は図 2 の通りで、A( 0, 0 ) や A (1, 2 ) とかは空白、A( 0, 1 ) や A( 1, 1 ) には値(*)が入っている状態になっている。
縦が添字 i の番号、横が添字 j の番号を表している。配列の位置を示す i や j のことを "添字(そえじ)" と呼ぶ。インデックスと呼ぶ人もいる。好みの世界。
これをどういったルールで B( i, j ) に入力すれば、図 3 となるような配列 B が出来上がるのか、といった問題である。
一個一個の空白や値(*)は区別できないが、配列 A と B の全体を眺めると、配列 A を時計回りに 90 度回転したら配列 B になることが分かる。
(配列で描かれている F の文字が右に倒れている。)
なので、F の左上部分 A( 0, 1 ) と対応しているのは B( 1, 7 ) であり、F の一番下部分 A( 7, 1 ) と対応しているのは B( 1, 0 ) ということになる。
つまり、流れ図のループの中で、以下のような代入があったことになる。
- B( 1, 7 ) ← A( 0, 1 )
- B( 1, 0 ) ← A( 7, 1 )
各選択肢をみて、上の代入と一致するものを探せばいい。
すると、選択肢エ B( j, 7-i ) ← A( i, j ) だけが一致することが分かる。
ということで、問題の正解は選択肢エである。
「回転」にパワー使ったからな。
元ネタわかってくれる同志はいるだろうか。
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/1d6e79a0.6eab03bd.1d6e79a1.59b07dcf/?me_id=1213310&item_id=16199243&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F6979%2F9784088706979.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問8
スタック(データ構造)についての問題。
--------------------------
令和元年度 秋期 午前 問8
A, C, K, S, T の順に文字が入力される。スタックを利用して、S, T, A, C, K という順に文字を出力するために、最小限必要となるスタックは何個か。ここで、どのスタックにおいてもポップ操作が実行されたときには必ず文字を出力する。また、スタック間の文字の移動は行わない。
ア 1
イ 2
ウ 3
エ 4
--------------------------
解説
スタックについてはこちらの問題で(雑な)絵とともに説明している。
スタックは先に入れたデータほど後に取り出されるデータ構造である。
この方式は LIFO(Last In First Out)と呼ばれる。
Last In(最後に入れたもの)が First Out(最初に取り出される)。
なので、一つのスタックに連続して文字を入力(プッシュ)すると、取り出す(ポップ)ときは逆の順序になる。
スタックの数が少ない選択肢から考えてみる。
スタックが 1 個の場合(選択肢ア)
- 最初にポップ操作で出力したい文字は "S" なので、"S" が入力されるまでの "A, C, K" はスタックに溜めておく必要がある。ということで、"A, C, K" は全てプッシュして同じスタックに入力することになる。
- 次に "S" がプッシュされた後すぐにポップ、その次に "T" がプッシュされた後すぐにポップ、とすれば "S, T" までは欲しい順序で出力できる。
- しかし、その後のポップ操作で出力されるのは "K, C, A" となってしまう("A, C, K" の順で同じスタックに入力しているので、逆の順序でしか取り出せない)。
スタックが 2 個の場合(選択肢イ)
- スタックが 1 個の場合を反省すると、"S" が入力されるまでの "A, C, K" は 3 文字とも別々のスタックに入力する必要があることが分かる。
- 上の理由は、"A, C, K" の 3 文字だけに着目すると、入力される順序も、欲しい出力の順序も同じであるためである。同じスタックに入力してしまうと順序が逆転して出力されてしまい、欲しい文字列の順序にならなくなってしまう。
- ということで、スタックが 2 個の場合は "S" が入力されるまでの "A, C, K" を別のスタックに入力しておくことができないので不正解となる。
スタックが 3 個の場合(選択肢ウ)
- スタックが 3 個あるので、"A, C, K" を別々にスタックに入れることができる。
- 次の "S" はどのスタックでもいいので入れて、すぐにポップしてしまう。その次の "T" も同じようにプッシュ&ポップ。
- 後は 3 つのスタックに分かれて入っている "A, C, K" を順番通りにポップすれば、"S, T, A, C, K" の順の出力を得ることができる。
- ということで、正解は選択肢ウとなる。
"S, T, A, C, K" を見てまず思いついたもの。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問7
BNF についての問題。
--------------------------
令和元年度 秋期 午前 問7
次の BNF で定義される <変数名> に合致するものはどれか。
<数字> :: = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<英字> :: = A | B | C | D | E | F
<英数字> :: = <英字> | <数字> | _
<変数名> :: = <英字> | <変数名><英数字>
ア _B39
イ 246
ウ 3E5
エ F5_1
--------------------------
解説
BNF とは、バッカス・ナウア記法(Backus-Naur Form) の略。
"文脈自由文法を定義するためのメタ言語" とのことであるが、この文章がまずわかりにくい。
文法(この問題だと "<変数名>" とかの構造)を定義するためのもの、と思えばいい。
<数字> :: = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
順番に見ていくとして、上の BNF における "<数字>" は 0 から 9 のどれかという意味になる。
なので、ここでは 10 とか 100 は "<数字>" ではない(定義に当てはまらない)。
"<数字><数字>" という BNF がもしあれば、10 とか 99 とかが当てはまる。
"<数字><数字><数字>" という BNF がもしあれば、100 とか 256 とかが当てはまる。
<英字> :: = A | B | C | D | E | F
次に上の BNF について。
ここでは "<英字>" は A か B か C か D か E か F のどれかという意味になる。
なので、ここでは Z は "<英字>" ではないし、2 文字以上でも "<英字>" ではない。
<英数字> :: = <英字> | <数字> | _
続いて上の BNF について。
"<英数字>" という定義の中に、先に説明した "<英字>" と "<数字>" が入っている。
"<英数字>" は "<英字>" か "<数字>" か _ のどれか、という意味になる。
"<英字>" と "<数字>" については上の説明の通り。
ということで、ここでは "<英数字>" は A, B, C, D, E, F, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, _ のうちどれか一文字という意味になる。
<変数名> :: = <英字> | <変数名><英数字>
最後の BNF について。
"<変数名>" の定義の中に自分自身である "<変数名>" が含まれていてややこしい。
"<変数名>" は "<英字>" か "<変数名><英数字>" のどちらか、という意味になる。
"<英字>" の場合は A, B, C, D, E, F のどれかなのでわかりやすい。
A の一文字だけでも、"<変数名>" の定義には当てはまることになる。
"<変数名><英数字>" の場合は再び "<変数名>" がでてきてしまう。
以下、少しでも見やすくするため <変数名> に色を付けてみる。
"<変数名>" は "<英字>" か "<変数名><英数字>" なので、
"<変数名><英数字>" は "<英字><英数字>" か "<変数名><英数字><英数字>" になる。
同じようにして、"<変数名><英数字><英数字>" は "<英字><英数字><英数字>" か "<変数名><英数字><英数字><英数字>" になる。
なんとなくパターンが見えてきた通り、"<変数名>" は
"<英字>"
"<英字><英数字>"
"<英字><英数字><英数字>"
"<英字><英数字><英数字><英数字>"
"<英字><英数字><英数字><英数字>・・・<英数字>"
といった様に先頭が "<英字>" で、その後ろに任意の数だけ "<英数字>" が続く BNF になる。
問題の各選択肢がこの定義にあっているかをみてみる。
選択肢ア "_B39"、選択肢イ "246"、選択肢ウ "3E5"、はどれも先頭が "<英字>" ではないので誤り。
選択肢エ "F5_1" は先頭が "<英字>" の定義に当てはまり、"<英字><英数字><英数字><英数字>" の BNF に合致する。ということで正解は選択肢エ。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問6
確率、疑似乱数についての問題。
--------------------------
令和元年度 秋期 午前 問6
Random(n) は、0 以上 n 未満の整数を一様な確率で返す関数である。整数型の変数 A、B 及び C に対して次の一連の手続を実行したとき、C の値が 0 になる確率はどれか。
A = Random(10)
B = Random(10)
C = A - B
ア
イ
ウ
エ
--------------------------
解説
確率の問題。
「Random(n) は、0 以上 n 未満の整数を一様な確率で返す関数」
とあるので、問題文の Random(10) が返す値は 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 の 10 種類のうちどれかであり(0 以上 n 未満の整数)、どれも確率は (一様な確率)となる。
A = Random(10)
B = Random(10)
なので、A と B の組合せ (A, B) のケースは A が 10 種類、B も 10 種類で、10 × 10 = 100 通りになる。
A と B の値はどれも一様な確率なので、この 100 通りも一様な確率で出現することになる。つまり、どれも出現する確率は になる。
100 通りある (A, B) のうち、C = A - B が 0 になるケースは A = B のときなので、
(A, B) = (0, 0)、(1, 1)、(2, 2)、(3, 3)、(4, 4)、(5, 5)、(6, 6)、(7, 7)、(8, 8)、(9, 9)
の 10 通りある。
(A, B) のどの組合せも出現する確率は一様なので、C = 0、つまり A= B となる確率は
(A = B となるケース数)/(全てのケース数)
=
ということで、問題の正解は選択肢ウ である。
Random(n) のような関数は実際に存在し、疑似乱数生成器と呼ばれる。
コンピュータ上で計算して乱数をつくる都合で真の乱数とはならないため、"疑似" とついている。
- 疑似乱数:一見すると乱数に見えるが、規則性や再現性がある。乱数の生成アルゴリズムとコンピュータの内部状況(計算過程)が分かれば、次の乱数が予測可能となってしまう。
- 真の乱数:規則性や再現性が一切ない。自然現象のような本当にランダムな現象をもとにしないと作れない。自然乱数とも呼ばれる。次の乱数は予測不可能である。
コンピュータ上で真の乱数を得るためには専用のハードウェアを用いることがある。
そのハードウェアだけで販売されているのかなと楽天を覗いてみたら、面白そうなものがでてきた。
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/2121fee1.9fe20323.2121fee2.55099e1f/?me_id=1401889&item_id=10000078&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fugears%2Fcabinet%2Fopen%2Fug-randomgenerator.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
画像だけ Web からコピペすると著作権侵害がこわいので、アフェリエイトの仕組みを活用しています。
もちろん、報酬はいったら嬉しいという下心はある(隠す気はない)。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問5
併せて、情報処理試験の問題複製についても。
--------------------------
令和元年度 秋期 午前 問5
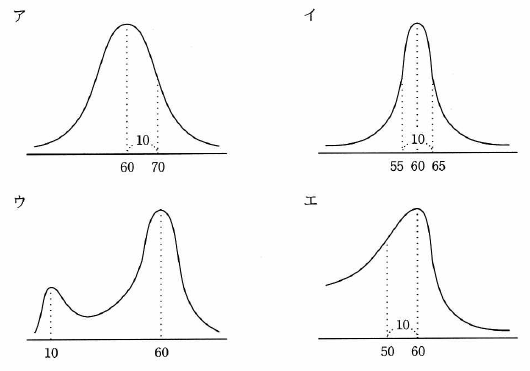
平均が 60、標準偏差が 10 の正規分布を表すグラフはどれか。
--------------------------
解説
選択肢を自分で書くのが大変そうなので、過去問からのコピーにて。
複製していいのか??は問題解いたあとに書いてます。
正規分布(Normal Distribution)
別名、ガウス分布(Gaussian Distribution)
確率分布の一種で、データが平均値の周りの集まるような分布をする。
以下の様な特徴がある分布になる。
- 平均値を中心にして、左右対称なグラフになる(選択肢ウと選択肢エは平均値 60 を中心に左右対称となっていないので簡単に除外できる)。
- 平均値を μ(ミュー。今回は 60)、標準偏差を σ(シグマ。今回は 10)としたときに、μ ± σ の範囲に全体の約 68% のデータが含まれる(選択肢イでは μ ± 0.5×σ の範囲でそれくらいのデータがすでに含まれているように見えるので、誤り)。
ということで、選択肢アが正解になる。
選択肢アと選択肢イのグラフに上記の説明を書き加えてみた図が以下になる。

問題や選択肢の中で説明はないけれども、グラフの書き方から、選択肢イの 55 ~ 65 の線は約 68% のデータが含まれる範囲を表現していると推測できる(= 選択肢イは平均が 60、標準偏差が 5 のグラフになっていると推測)。
標準偏差 σ が小さいほど、正規分布の山は尖った形状になる。
以下は問題からは脱線して、過去問のデータを複製/コピーしていいのか??について。
IPA 独立行政法人 情報処理推進機構:情報処理技術者試験:よくある質問
上のリンクで IPA の Web ページ(よくある質問)が開く。
「7. その他」 の中に「試験の過去問題の使用方法(申請方法、使用料等)について教えてください。」といった質問がある。
内容は以下の通り。
=========================
当機構で公表している過去の試験問題の使用に関し、許諾や使用料は必要ありません。(ダウンロードでのご利用も特に問題ございません。)
ただし、以下の留意点を必ず確認の上、ご使用ください。(追記:許可を得たり使用料を払うことなく過去問は利用していいとのこと。ただし、留意点を守る必要がある。)
【留意点】
- 著作権は放棄していません。(追記:著作権は IPA が保持したままなので、利用はしてもいいが、自分でその問題を作ったかの様に見せてはいけない。後にでてくるが、出典を書いて IPA からコピーしていることを明記する必要がある。)
- 教育目的など、情報処理技術者試験制度、情報処理安全確保支援士制度の意義に反しない限り、公表されている過去問題を問題集やテキストに使用される際、許諾および使用料の必要はありません。(追記:情報処理の促進に寄与するような利用方法であればいいけど、そうでない場合は事前に許可をもらう必要がある。)
- 出典を以下のように明記してください。(年度、期、試験区分、時間区分、問番号等)[例]「出典:平成31年度 春期 基本情報技術者試験 午前 問1」また、問題の一部を改変している場合、その旨も明記してください。(追記:いつの問題を複製したかが分かるようにする必要がある。また、問題を改変している場合はどのように改変したかも分かるようにする必要がある。)
- 公表しているPDF以外の電子データの提供はできません。(PDFセキュリティの解除方法は提供できません。)(追記:加工したいから Word のデータをくれ、とかはいってはいけない。)
=========================
といった非常に寛大なルールになっている。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問4
極限、無限大、が含まれる数式の問題。
--------------------------
令和元年度 秋期 午前 問4
および
を定数とする関数
及び
に対して、
はどれか。ここで、
、
、
とする。
ア 0
イ 1
ウ
エ ∞
--------------------------
解説
この問題で初めて、はてなブログで数式を書く方法を知りました。
TeX と同じような書き方ができるのね。
確率や 2 進数といった数学を絡ませた情報処理の問題は多いけど、これはがっつりと数学の問題になっている。
このような無限大への極限がある問題では、 であることを利用する。
分子が 1 ではなく a や b などの定数であっても、分母が限りなく大きくなれば、その分数は 0 に近付いていく。
、
なので、
となる。
これの分子と分母を で割ると以下のようになる。
ここで、 でもある(分母が大きくなるスピードが
の場合よりも早くなるだけ)ので以下のようになる。
問題文から a ≠ 0 であるので、問題の正解は選択肢アの 0 になる。
(a = 0 の可能性がある場合、分母が 0 となってしまうので NG な分数になってしまう。)
上記は真面目な解き方。
楽な解き方として以下のような考え方もある。
も
も
で 0 に近付く。
- どちらも 0 に近付くが、
よりも
の方が小さくなるスピードが早いので)。
は分子の方が先に小さくなって 0 に近付いていく。つまり、分数としても 0 に近付いていく。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問3
データ構造におけるグラフ、無向グラフ、有向グラフ、隣接行列についての問題。
--------------------------
令和元年度 秋期 午前 問3
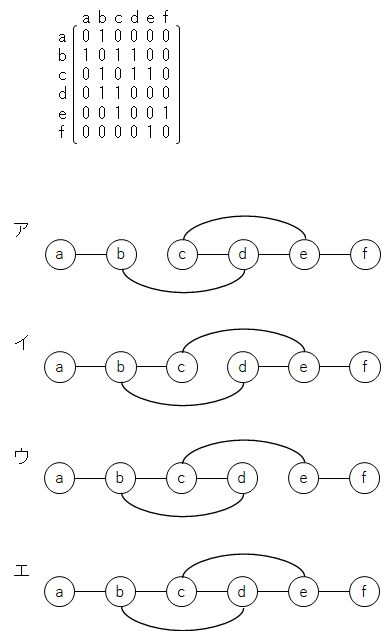
ノードとノードの間のエッジの有無を、隣接行列を用いて表す。ある無向グラフの隣接行列が次の場合、グラフで表現したものはどれか。ここで、ノードを隣接行列の行と列に対応させて、ノード間にエッジが存在する場合は 1 で、エッジが存在しない場合は 0 で示す。
--------------------------
解説
データ構造におけるグラフの問題。
データ要素であるノード(節点、点)とそのノード間のつながりを示すエッジ(辺、線)でデータ構造を示すもの。
この問題の場合、ノードは a や b 、エッジはそれらを繋ぐ線で表現されている。
a や b が電車の駅名であれば、路線図の様になる(エッジがある = 線路が直接つながっている)。
グラフで表現しているデータ構造は、隣接行列でも表現できる。

上は問題文の隣接行列に色々と書き込んだもの。
問題文には "ノードを隣接行列の行と列に対応させて、ノード間にエッジが存在する場合は 1 で、エッジが存在しない場合は 0 で示す" とある。
- 青色で協調している行を見れば、ノード a とその他のノード ( b ~ f ) との間にエッジが存在するかがわかる。1 になっている部分は a - b のみなので、ノード a はノード b とのみエッジをもっている。
- 橙色で協調している行を見れば、ノード d とその他のノード( a, b, c, e, f ) との間にエッジが存在するかがわかる。1 になっている部分は d - b と d - c なので、ノード d はノード b および ノード c とエッジをもっている。
- 各ノードは自分自身とはエッジをもたないため、赤線部分は全て 0 になる。また、この行列は赤線で対称になっている。この問題は無向グラフ(向きが無い)なので、"a から見た b との繋がり" と "b から見た a との繋がり" が等価になる。有向グラフ(向きが有る)の場合、一方通行のようなエッジが存在するので等価とはならず、赤線で対称にはならなくなる。
どの選択肢もノード a はノード b とのみエッジをもっているので、ノード a に関しては正しい。
ノード d を見ると、ノード b とノード c とのみエッジをもつ選択肢はウのみである。
ということで、正解は選択肢ウになる。
ちなみに、有向グラフの場合はノード間のエッジが向きをもつ矢印の様になるので、以下のようなグラフと隣接行列になる(はず)。
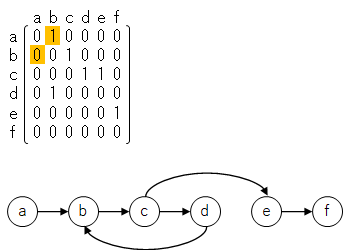
橙色の部分、a から見た b は 1 になるが、b から見た a は 0 となっている。
これは a → b という向きをもつエッジを表現している。
前後の問題はこちら。