基本情報技術者試験 令和元年度 秋季 午前 問27
関係モデルの演算についての問題。
--------------------------
令和元年度 秋期 午前 問27
関係モデルにおいて、関係から特定の属性だけを取り出す演算はどれか。
ア 結合(join)
イ 射影(projection)
ウ 選択(selection)
エ 和(union)
--------------------------
解説
関係モデルの演算についての問題。
平成 31 年度春期の午前問題で類似の問題があったので、そちらで演算については書いていたらしい(記憶がおぼろげ)。
ということで正解はイの射影(projection)になる。
ここで終わると過去最短の記事になりそうなので何か書かないと。
平成 31 年度の問題では選択肢は以下。
ア 結合(join)
イ 射影(projection)
ウ 選択(selection)
エ 併合(merge)
一方で、令和元年の問題では選択肢は以下。
ア 結合(join)
イ 射影(projection)
ウ 選択(selection)
エ 和(union)
選択肢が一部変わっている。併合(merge)が和(union)に。
演算の内容は異なるものの、行を追加する様な演算であるところは同じ。
各演算のイメージを図示すると以下の様になる。
まずは関係(≒表)に行や列を追加する演算から。

- 和(union)や併合(merge)は行を追加する様なイメージ
- 結合(join)は列(=属性)を追加する様なイメージ
次は関係(≒表)から行や列を取り出す演算を。

- 射影(projection)は列(=属性)を取り出す様なイメージ
- 選択(selection)は行を取り出す様なイメージ
データベースのソフトウェアは Oracle や PostgreSQL、MySQL あたりがよく聞く。
クラウドの AWS(Amazon Web Services)のデータベースサービスである RDS でも PostgreSQL や MySQL をエンジンとして選択できる。
SQL による操作方法はほぼ同じであるが、ソフトウェアによって微妙に方言や挙動が異なる。
一方で、情報処理試験のデータベーススペシャリストは各ソフトウェアに固有のものは問題にでてこないので、取得を目指すとデータベースに関する技術の根幹を学習することができる。
資格をもっていても実務に役に立たないと言われてしまうことはあるけれど、技術の根幹を理解していると、どのソフトウェアを使うにしても慣れが早くなる。と思う。
情報処理試験は勉強しておいて損はないはず。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問26
SQL 文の問題。HAVING と WHERE の使い分け。
--------------------------
令和元年度 秋期 午前 問26
"得点" 表から、学生ごとに全科目の点数の平均を算出し、平均が 80 点以上の学生の学生番号とその平均点を求める。a に入れる適切な字句はどれか。ここで、実線の下線は主キーを表す。
得点(学生番号、科目、点数)
[ SQL 文 ]
SELECT 学生番号、AVG(点数)
FROM 得点
GROUP BY 【 a 】
ア 科目 HAVING AVG(点数)>= 80
イ 科目 WHERE 点数 >= 80
ウ 学生番号 HAVING AVG(点数)>= 80
エ 学生番号 WHERE 点数 >= 80
--------------------------
解説
問題となっている表は "得点" で、その形は以下のようになっている。
- 得点(学生番号、科目、点数)
この表から、学生ごとに全科目の点数の平均を算出する必要がある。
SQL 文の問題で上のように平均(AVG)がほしい場合には GROUP BY 句が使われる。
GROUP BY 句は指定した要素ごとに、他の要素の平均(AVG)、合計(SUM)、最大(MAX)、最小(MIN)、個数(COUNT)を計算することができる。
回答の選択肢は 2 パターンに分けられて、"GROUP BY 科目" か "GROUP BY 学生番号" のどちらかを用いている。
| 学生番号 | 科目 | 点数 |
| 1001 | 国語 | 60 |
| 1002 | 国語 | 80 |
| 1001 | 数学 | 70 |
| 1002 | 数学 | 90 |
得点表が上のようなケースであった場合、"GROUP BY 科目" とした場合は以下のような表が作られているイメージになる(実際に表が作られている訳ではない。はず。)。
| 科目 | AVG(点数) | MAX(点数) | MIN(点数) | SUM(点数) | COUNT(*) |
| 国語 | 70 | 80 | 60 | 140 | 2 |
| 数学 | 80 | 90 | 70 | 160 | 2 |
"科目 = 国語" の行で集計された結果と、"科目 = 数学" の行で集計された結果がわかる。
各科目ごとの平均点や最高得点などはわかるけれど、学生番号ごとの区別は集計をする際に消えてしまっていることがわかるので、問題が聞いている "学生番号ごと" の平均点はわからなくなってしまう。
もう一方の "GROUP BY 学生番号" とした場合は以下のような表が作られているイメージになる(略)。
| 学生番号 | AVG(点数) | MAX(点数) | MIN(点数) | SUM(点数) | COUNT(*) |
| 1001 | 65 | 70 | 60 | 130 | 2 |
| 1002 | 85 | 90 | 80 | 170 | 2 |
このときの AVG(点数)は国語と数学の平均点(=全科目の点数の平均)になるので、問題が聞いている "学生ごとの全科目の点数の平均" が計算できていることになる。
ということで、"GROUP BY 学生番号" にする必要があるため、正解の選択肢はウかエになる。
- ウ 学生番号 HAVING AVG(点数)>= 80
- エ 学生番号 WHERE 点数 >= 80
異なる点は HAVING 句か WHERE 句を使っているかであるが、"平均が 80 点以上" という条件なので、 "AVG(点数)>= 80" を指定していなければおかしい。
なので、問題の正解は選択肢ウの "学生番号 HAVING AVG(点数)>= 80" になる。
選択肢エは "点数 >= 80" なので、平均ではなく全ての科目の点数に対して 80 点以上かを確認してしまっている。
HAVING 句と WHERE 句はどちらも条件を満たす行を抽出するために使われるが、明確な使い分けが必要になる。
誤りを恐れずざっくり書くと以下のような使い分けをすれば良い。
- HAVING 句は GROUP BY で集計した後の表にでてくる要素 "AVG(点数)" や "MAX(点数)" などを条件に指定する際に用いる。
- WHERE 句は GROUP BY で集計する前の、もともとの表にある要素 "科目" や "点数" などを条件に指定する際に用いる。
厳密には HAVING 句でもともとの表にある要素を指定することができたりもするけれど。気にしない。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問25
UML(Unified Modeling Language :統一モデリング言語)についての問題。
--------------------------
令和元年度 秋期 午前 問25
UML を用いて表した図の概念データモデルの解釈として、適切なものはどれか。

ア 従業員の総数と部署の総数は一致する。
イ 従業員は、同時に複数の部署に所属してもよい。
ウ 所属する従業員がいない部署の存在は許されない。
エ どの部署にも所属しない従業員が存在してもよい。
--------------------------
解説
UMA(Unidentified Mysterious Animal:未確認動物)を思い出す。
子どものころはチュパカブラが怖かった。
結局なんだったのだろうか。
UML については以前も書いている。
図が無いので不親切な記事であるが、UML についてはググるといくらでも図付きの説明がでてくるので是非そちらを参照してほしい(UML は種類がおおいので沢山の図をつくりたくない)。
問題に戻る。
問題の図はクラス図であり "部署" や "従業員" といった要素(クラス)間の関係を示すために作られる。

説明のために一部を塗りつぶしている。
この図から分かることは以下の通り。
- "部署" と "従業員" という要素(クラス)間に "所属する" という関係がある。
- "従業員" というクラスは、1 以上かつ複数(1..*)の "部署" と "所属する" の関係がある。
要は、この企業では従業員は必ずどこかの部署に所属していて、かつ、複数の部署に所属していることがあり得るということになる。
従業員は 1 つ以上の部署と所属している関係がないといけないので、どこにも所属していない従業員は存在しないということ。
新入社員も入社直後から所属部署が決まっているのか、もしくは、未配属を示すダミーの部署情報が存在するのか、などと妄想してみる。

塗りつぶす位置を変えて、この図から分かることは以下の通り。
- "部署" と "従業員" という要素(クラス)間に "所属する" という関係がある。
- "部署" というクラスは、0 以上かつ複数(0..*)の "従業員" と "所属する" の関係がある。
要は、この企業では従業員の存在しない部署があり得るということになる。
新設の部署を作るときなどに、とりあえず部署の情報だけシステムに登録することが可能になっている。
管理者やルールがしっかりしていれば問題ないけど、雑な管理をしだすと(仮)とつく部署がたくさん登録されてしまいそう。などと妄想してみる。
あとは上で書いた内容と選択肢を比較してみる。
- アは「従業員の総数と部署の総数は一致する。」は違う
- イは「従業員は、同時に複数の部署に所属してもよい。」は合っている
- ウは「所属する従業員がいない部署の存在は許されない。」は違う
- エは「どの部署にも所属しない従業員が存在してもよい。」は違う
ということで正解は選択肢イになる。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問24
--------------------------
令和元年度 秋期 午前 問24
H.264/MPEG-4 AVC の説明として、適切なものはどれか。
ア
5.1 チャンネルサラウンドシステムで使用されている音声圧縮技術
イ
携帯電話で使用されている音声圧縮技術
ウ
ディジタルカメラで使用されている静止画圧縮技術
エ
ワンセグ放送で使用されている動画圧縮技術
--------------------------
解説
MPEG という文字列に見覚えがあればこっちのもの。
MPEG は動画ファイルでよく使われている拡張子。
選択肢の中で動画になっているのは一つだけなので、正解は選択肢エとなる。
Windows だと拡張子を表示するようにしていれば目にすることも多そうだけど、拡張子を表示するのが当然なのはシステムエンジニアだからでしょうか?
動画の規格としての MPEG は略称ではないらしい。
Moving Picture Experts Group (=動画の専門集団)というそのままな名称のグループが作った規格なので、規格の正式名称が MPEG なのだとか。
(グループ名としては MPEG は略称で、動画圧縮技術の規格名としては MPEG は略称ではなく正式名称になるということ。)
MPEG-4 AVC と技術は同じであるが制定した団体が違うのが H.264 になる。
H.264 とか MPEG といった単語がでてきたら動画の圧縮技術だろうと考えればよい。
似ている規格で、写真データでみかける JPEG がある。
こちらも規格としては略称ではなくて Joint Photographic Experts Group (=写真(?)の専門集団)というそのままな名称のグループが作った規格である。
拡張子の表示に関して。
個人的には、メリットがあるので表示するように設定した方が良いと思う。
メリットの一つとしてはセキュリティ向上。
メールに添付されているファイルが "案内図.jpg" とあるので開いてみたら実はウイルスの実行ファイルであったというケースがある。
カラクリとしては "案内図.jpg" の実際の名称が "案内図.jpg.exe" であるというもの。
拡張子の表示をしない設定だと末尾の .exe は表示されないので、"案内図.jpg" と見た目は画像ファイルになってしまう(アイコンの画像も偽装する方法はある)。
「拡張子が表示されない設定にしているのだから、表示されていたら疑うはず」というツッコミももちろんあるけど、残念なことにこれが意外と疑われない。
(セキュリティ訓練の数値を見ると、結構な割合で、怪しいファイルでも開封されてしまっていることが分かる)
この問題のように拡張子を表示して見慣れていれば解きやすくなるといったメリットもありそうなので、表示をオススメします。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問23
コード体系についての問題。
--------------------------
令和元年度 秋期 午前 問23
コードから商品の内容が容易に分かるようにしたいとき、どのコード体系を選択するのが適切か。
ア 区分コード
イ 桁別コード
ウ 表意コード
エ 連番コード
--------------------------
解説
コード:code
名詞としては記号、符号、規範、規約、など。
他動詞としてはプログラムする、暗号にする、など。
自動詞としては死亡するという意味があるらしい。急な変化。ほんと?
各選択肢のコードを解説する。
選択肢ア:区分コード(分類コード)
似ている項目毎に区別をつけるようにしたコードのこと。
例えばスーパーマーケットで、
- A0001 ~ A9999 は野菜のコード
- B0001 ~ B9999 は魚のコード
とするようなもの。
A で始まるものは野菜、B で始まるものは魚と区別がつく。
一方で、前提知識なしで番号(例えば A0226)だけ見てもそこから内容を推測することはできないので、問題が聞いているように商品の内容を推測することはできない。
Linux のユーザ ID(uid) でこの考え方を使うことをよく目にする。
- uid=2000 番台はシステム管理者向け。
- uid=4000 番台は通常利用者向け。
通常利用者が 1000 人以上いると 4000 番台だけでは足りなくなるので考慮が必要。
それを気にしないで安易に 5000 番台を使いだすと管理ツールで不具合が起きたりする。
選択肢イ:桁別コード
コードの各桁の位置ごとに意味があるコードのこと。
学生番号や社員番号でよく使われている。
2021 年度の情報学科(08)の名前順で 26 番目の学生番号は 2021080026 とか。
※ "2021" "08" "0026" をつなげたもの。
申込の受付番号とかにもよく利用されている。
e-Tax で確定申告すると、受付番号が 2021-0218-1632-1621-1230 のようになる。
先頭から 2021年、2月 18日、16時 32分、あとは秒と、追加の情報かな。
全て時間だけにすると全く同時の申請に同じ受付番号が振られて誤動作を起こすことがあり得るので、それを回避するような仕組みは必要。
選択肢ウ:表意コード
表意の名前の通り、"意" 味を "表" すコードということ。
コードを見ればなんとなく意味(内容)がわかるようなコードのこと。
問題文の「コードから商品の内容が容易に分かるようにしたいとき」ともあっているので、問題の正解は選択肢ウの表意コードになる。
表意コードでよくみかけるのは国名を表すコード。
- 3桁のもの JPN、USA、ITA(ISO 3166-1 alpha-3)
- 2桁のもの JP、US、IT(ISO 3166-1 alpha-2)
何も前情報がなくても、JPN、USA 、ITA と書いてあれば国のことだろうとわかる。
選択肢エ:連番コード(順番コード)
データに対して順番に連続した番号を割り当てるコードのこと。
当然、コードの番号から内容を推測することはできない。
データベースにデータを格納するときに主キーにできる属性が無い場合に、追加で連番コードを振って主キーとすることがある。
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問22
論理回路の問題。
--------------------------
令和元年度 秋期 午前 問22
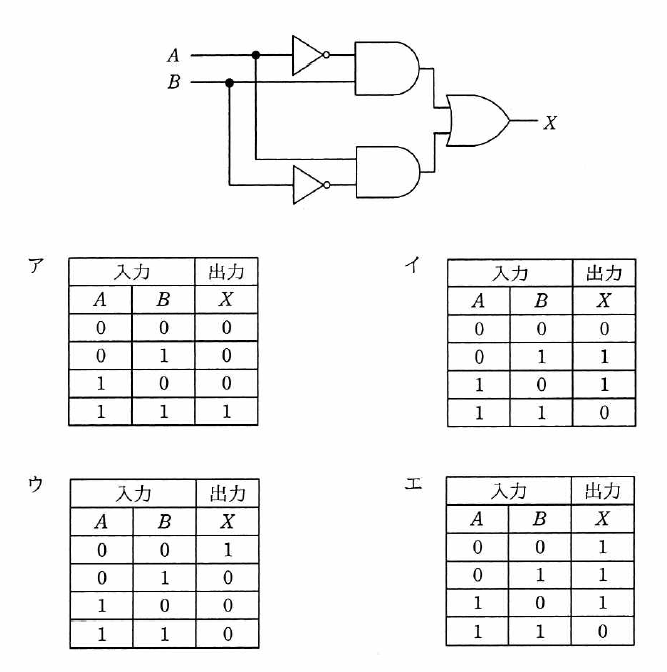
--------------------------
解説
論理回路の問題は泥臭く値を当てはめて確認すれば確実に回答できるので、間違えないようにしたいところ。
A と B の全ての組合せを試しても 4 通りしかないので、焦らずにやっても時間はかからない。
論理回路の図記号は問題用紙の最初の方にルールが記載されているので覚えている必要はない。
周りで問題用紙のページを慌ただしく戻す音がしたらこの問題まできたのだろうなと。
図に 1、0 を書き込むとか論理式を書いてしまうとか好みはあるけれど、論理式を一度書いてしまう方がケアレスミスを減らせる気がする。

ということで、問題の論理回路の各ポイントに論理式を書き込むと上の図のようになる。
登場している図記号を大まかに説明すると、
- 論理否定素子(NOT)は入力を反対にした出力をする。入力が 0 なら 1、入力が 1 なら 0 を出力する。表記は
のように上に線がつく。
- 論理積素子(AND)は 2 つの入力が両方とも 1 の場合だけ出力が 1 になる。その他の場合は全て出力は 0 になる。表記は
のようにドットでつなぐ。
- 論理和素子(OR)は 2 つの入力のうちどちらかが 1 であれば出力が 1 になる。出力が 0 になるのは入力がどちらとも 0 の場合のみ。表記は
のようにプラスでつなぐ。
最終的な出力は となる。
途中経過も含めて以下の様な真理値表をざっと書くと計算しやすくなる。
| A | B | |||
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 |
これと同じ真理値表である選択肢イが正解である。
このような出力 X を持つ回路は排他的論理和(XOR)と呼ばれる。
2 つの入力が異なる場合のみ出力が 1 になるというもの。
XOR とかのベン図はこちらで解説している。(改めて書くのが面倒。。。)
前後の問題はこちら。
基本情報技術者試験 令和元年度 秋季 午前 問21
シフトレジスタ?ストロープ?エッジ?となる問題。
--------------------------
令和元年度 秋期 午前 問21
クロックの立上りエッジで、8 ビットのシリアル入力パラレル出力シフトレジスタの内容を上位方向へシフトすると同時に正論理のデータをレジスタの最下位ビットに取り込む。また、ストロープの立上りエッジで値を確定する。各信号の波形を観測した結果が図のとおりであるとき、確定後のシフトレジスタの値はどれか。ここで、数値は 16 進数で表記している。

ア 63
イ 8D
ウ B1
エ C6
--------------------------
解説
問題文に耳慣れない単語がでてきて一瞬戸惑うけど、問題を解くために考えることは非常に単純な問題。
まずは問題文の言葉を説明しておく。
"クロックの立上りエッジで"
簡単な言葉にすると "クロックの波形が立ち上がったタイミングで" になる(あまり変わらないか)。
図にそのタイミングをオレンジの矢印で追加してみる。

上の図の 10 箇所が、該当するタイミングになる。
"8 ビットのシリアル入力パラレル出力シフトレジスタの"
シリアル入力パラレル出力は言葉の通りで、入力の口は一つ(シリアル)であるけど出力の口は複数(パラレル)ということ。
この部分は問題を解くのに必須な情報ではないので、無視して OK。
レジスタはデータを保管する場所と思えばよく、シフトレジスタは保管されているデータ(ビット)がシフト(スライド)できるようになっているレジスタのこと。

8 ビットのシフトレジスタを図にしてみると上の様になる。
上段のレジスタの状態から、内容を上位方向へシフトすると下段の状態になる。
- シフト前の最上位ビットはシフト先がないので、情報はなくなってしまう。
- シフト後の最下位ビットは別のところからデータを持ってくる必要がある(次の部分で説明)。
"内容を上位方向へシフトすると同時に正論理のデータをレジスタの最下位ビットに取り込む"
クロックの立上りエッジにて、シフトレジスタの内容を上位方向にシフトして、さらに、シフトレジスタの最下位ビットに正論理のデータを取り込む。
上の図でオレンジの矢印のタイミング毎に以下の操作を実施するということ。
"正論理" とは、電圧の高い方を 1、電圧の低い方を 0 に対応させること。
※この逆に対応させること(電圧の高い方が 0 とする)を負論理と呼ぶ。

クロック立上りエッジ毎においてシフトレジスタの最下位ビットに取り込まれるデータをオレンジの矢印の下に書き足している。
データは正論理なので、電圧が高いときは 1、低いときは 0 となる。
"また、ストロープの立上りエッジで値を確定する"
クロックではなく、ストロープの波形が立ち上がったタイミングでシフトレジスタの値を確定させる。

ストロープの波形が立ち上がったタイミングを青の矢印で示している。
このタイミングでシフトレジスタの値が確定した場合、その値はいくつになるか?
がこの問題が聞いていること。
時間の矢印の方向は右でありシフトレジスタは 8 ビットなので、青の矢印のタイミングにおけるシフトレジスタは "(上位)1 0 0 0 1 1 0 1(下位)" になる。
最下位ビットに 1, 1, 0, 0, 0, 1, 1, 0, 1 の順に取り込むので、一番最初の 1 は 8 ビットに収まらず消えている。
これを 16 進数にすると 1 0 0 0 = 8、1 1 0 1 = D となるので 8D になる。
ということで正解は選択肢イの 8D である。
ストロープという単語を調べてみたけどよくわからなかった。。。
前後の問題はこちら。